
IWU")
Vorgehensmodell für Maschinelles Lernen in der Produktionsumgebung
Sina Nahvi
Machine Learning for Production (ML4P) ist ein Leitprojekt der Fraunhofer-Gesellschaft. Sechs Fraunhofer-Institute forschen in dessen Rahmen an einem werkzeuggestützten Vorgehensmodell, mit dem systematisch das Optimierungspotential von Produktionsanlagen durch das Nutzen von künstlicher Intelligenz untersucht wird. Im Folgenden werden die Erkenntnisse und die Vorgehensweise näher betrachtet.
In dieser Ausgabe unserer Nachgelesen-Reihe erfahren Sie:
- die Grundlagen des Maschinellen Lernens in der Produktion
- mehr über ein Vorgehensmodell zur Implementierung von Maschinellem Lernen in die eigenen Produktionsprozesse
Maschinelles Lernen in der Produktion
Der Wunsch nach Integration von Methoden des Maschinellen Lernens in bestehende Produktionsanlagen nimmt in der Industrie immer mehr zu. Problemstellungen, die ansonsten nur mit großem Aufwand gelöst werden könnten, sind durch Maschinelles Lernen (ML) effizient und effektiv lösbar geworden. Dies schafft neue Möglichkeiten bei der Verbesserung von Produktionsprozessen. Dabei reichen die Problemfelder über verbesserte Produktionsplanung und Bilderkennung bis hin zu vorausschauender Instandhaltung.
Die konkrete Implementierung stellt für viele Unternehmen eine neue Herausforderung dar. Erfahrungen und Wissen von ML-Experten, Prozessexperten und Automatisierungsingenieuren müssen zusammengeführt und gemeinsame Arbeitsabläufe entwickelt werden. Dies wird erschwert durch die Tatsache, dass eine solche Integration Eingriffe in ein laufendes System bedeutet. Die Wahrscheinlichkeit von Fehlern oder Ausfällen muss möglichst gering gehalten werden.[1]
Das ML4P-Vorgehensmodell
Das ML4P-Vorgehensmodell setzt an dieser Herausforderung an. Durch ein strukturiertes Wissensmanagement wird die Zusammenarbeit in interdisziplinären Teams optimiert. Ein linearer Ablauf über sechs Entwicklungsphasen erlaubt die sichere Entwicklung und Implementierung der Lösung. Innerhalb der Phasen werden agile Entwicklungsmethoden genutzt. Hierdurch können die Vorteile von agiler Softwareentwicklung mit den Anforderungen an Sicherheit, Robustheit und Dokumentation in Einklang gebracht werden. Einen Überblick der einzelnen Phasen gibt Abbildung 1. Die Phasen werden nachfolgend genauer erläutert.

Abbildung 1: Phasen des Vorgehensmodells
Um ein transparentes Wissensmanagement im Sinne durchgängiger Daten- und Dokumentenstrukturen zu etablieren, werden initial zwei digitale Dokumente eingeführt und für alle weiteren Phasen des Vorgehensmodells zur Dokumentation des aktuellen Entwicklungsstandes verwendet:
- einerseits die virtuelle Prozessakte und
- andererseits das ML-Pipeline-Diagramm.
Beide werden über den gesamten Entwicklungs- und Betriebszeitraum entwickelt und mitgeführt und sollen die Über- und Weitergabe von Projektergebnissen und Aufgaben innerhalb und zwischen Projektteams unterstützen.
Die virtuelle Prozessakte bündelt alle Informationen zum untersuchten Produktionsprozess, die über den Zeitraum der Entwicklung und der Implementierung erfasst wurden. Somit stellt sie die Dokumentation des Projekts von der Anfangsphase bis zum laufenden Betrieb dar.
Das ML-Pipeline-Diagramm (Abbildung 2) bietet eine visuelle Darstellung der Datenverarbeitung und der im Produktionssystem anfallenden Datenflüsse. Hierdurch wird eine Übersicht über die geplanten Maßnahmen geschaffen. Gleichzeitig ermöglicht es eine effiziente Kommunikation mit anderen Teams oder Abteilungen.
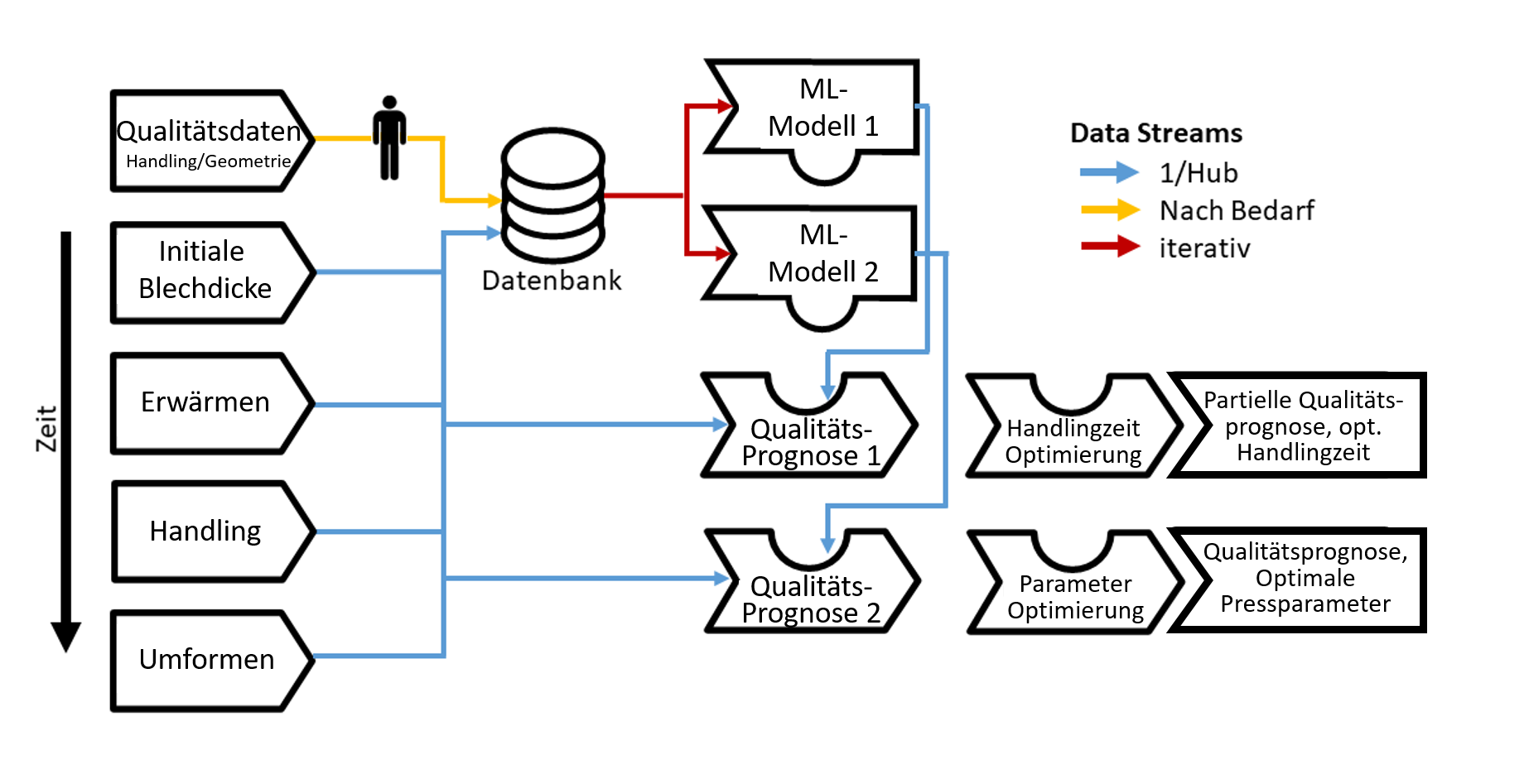 Abbildung 2: ML-Pipeline-Diagramm
Abbildung 2: ML-Pipeline-Diagramm
Phase 1: Analyse und Zielsetzung
Zuerst werden grundlegende Wirkzusammenhänge in einem interdisziplinären Team aus Machine Learning (ML)- und Prozessexperten analysiert. Aus den Ergebnissen wird ein Lösungsansatz, basierend auf Methoden des Maschinellen Lernens, entworfen. Anschließend werden messbare Projektziele definiert und dafür notwendige Maßnahmen abgeleitet.
Um den Zusammenhang zwischen Maßnahmen und dem Wirkeingriff im Produktionsprozess darzustellen, wird das initiale ML-Pipeline-Diagramm angelegt. Zunächst stellt es den idealisierten Datenverarbeitungsablauf dar. Weiterhin wird die virtuelle Prozessakte in dieser Phase angelegt. Initial werden hier der Prozess und Anlagenaufbau beschrieben. Die zur Verfügung stehenden Daten werden dokumentiert und die zuvor entwickelten Ziele und abgeleiteten Maßnahmen festgehalten. Abschließend werden die Projektrollen definiert. Dies gewährleistet, dass für alle benötigten Aufgaben entsprechende Experten zur Verfügung stehen und eine Verantwortungsdiffusion verhindert wird.
Somit sind am Ende der ersten Phase die Projektziele definiert, das ML-Pipeline-Diagramm für die Umsetzung entworfen und die virtuelle Prozessakte für das Wissensmanagement angelegt.
Phase 2: Funktionsnachweis
In der zweiten Phase wird ein Funktionsnachweis („Proof of Concept“) erarbeitet. Dieser wird außerhalb des Produktionssystems und mit einem kleinen, bereits vorliegenden Datensatz entwickelt.
Durch die Darstellung von Analysemodellen sollen die Überlegungen aus der ersten Phase validiert werden. Hierfür wird ein zyklisches Modell verwendet. Zunächst wird eine Hypothese aufgestellt. Die benötigten Daten werden gesammelt und ein entsprechendes Modell entwickelt. Die Ergebnisse dieses Modells werden anschließend evaluiert. Erzielt das Modell nicht die gesetzten Ziele, wird die ursprüngliche Hypothese angepasst. Anschließend wird ein neues Modell entwickelt, evaluiert und der Kreislauf wiederholt sich. Hierdurch ist eine stufenweise Verbesserung möglich und im Ergebnis erhält man einen sehr robusten Ansatz. Die Erkenntnisse dieser Phase fließen anschließend in die virtuelle Prozessakte und das ML-Pipeline- Diagramm ein.
Phase 3: Systemspezifikation
Aufbauend auf dem Funktionsnachweis werden in dieser Phase die konkreten Voraussetzungen für die Implementierung des Lösungsansatzes in die bestehende Anlage definiert. Im Vordergrund steht der geplante Übergang von einer manuellen Datenverarbeitung, wie in Phase 2, zu einer automatisierten Datenverarbeitung und die Integration des Lösungsansatzes in das bestehende Produktionssystem.
In dieser Phase muss definiert werden, welche Anpassungen an bestehenden Prozessen vorgenommen und welche neuen Prozesse eingeführt werden müssen. Hierbei ist der Austausch zwischen den einzelnen Experten von besonderer Bedeutung. Denn diese müssen sich gegenseitig über die Restriktionen der Prozesse, der Methoden des Maschinellen Lernens und der technischen Systeme informieren. Nur so kann eine Lösung zur Umsetzung geführt werden.
Phase 4: Umsetzung und Inbetriebnahme
In Phase 4 werden die zuvor festgelegten Systemspezifikationen schrittweise umgesetzt. Dabei ist die Beteiligung der ML-Experten nicht zwingend nötig und bei entsprechender Vorarbeit können die Umsetzungsschritte auch von externen Dienstleistern durchgeführt werden.
Abschließend kann die Inbetriebnahme vorgenommen werden. Zeitlich wird diese zumeist in Ruhezeiten (Wartungszeiträume oder Betriebsferien) gelegt, um Ausfallzeiten im Alltagsbetrieb möglichst gering zu halten. Bei der Inbetriebnahme müssen zwingend alle beteiligten Akteure aus Phase 3 anwesend sein. Falls es zu Problemen oder Überarbeitungsbedarf kommt, wird in dieser Phase zu einem agilen Arbeitsablauf übergegangen. In diesem Rahmen wird das Feedback aus der aktuellen Phase für Veränderungen der Systemspezifikationen aus Phase 3 verwendet.
Phase 5: Übergabe
Als Nächstes wird dem Anlagenbetreiber ein Inbetriebnahmeprotokoll übergeben. Dies geht einher mit einer Schulung der Mitarbeiter über die nun integrierten ML-Komponenten. Dies ermöglicht dem Betreiber eine Nutzung und Wartung der Anlage im Regelfall ohne eine Konsultation der externen ML-Experten.
Teil dieser Übergabe ist die Weitergabe der gesamten Dokumentation an den Anlagenbetreiber. Dies gibt dem Betreiber die komplette Kontrolle über die eingeführte ML-Lösung und ermöglicht ihm eine weitere Dokumentation der Prozesse.
Phase 6: Betrieb
Die letzte Phase stellt einen stetigen Prozess der Dokumentation und Anpassung des Systems dar. Nach der Inbetriebnahme muss die implementierte Lösung regelmäßig auf ihre Validität hin überprüft werden. Denn insbesondere nach Änderungen der Prozessabläufe sind solche Validierungen zwingend notwendig. Veränderungen müssen in der virtuellen Prozessakte dokumentiert werden und können auch dazu führen, dass das ML4P-Vorgehensmodell erneut durchlaufen werden muss, mit dem Ergebnis eines neuen ML-Modells, welches an die Veränderungen angepasst ist.
Deshalb stellt diese Phase weniger eine abzuschließende Phase dar, sondern mehr eine Phase, die solange aktiv ist, wie die implementierte Lösung Anwendung im Unternehmen findet.
Zusammenfassung ML4P
ML4P bietet Unternehmen und externen ML-Experten einen strukturierten Weg zur Implementierung von ML-Methoden in Produktionsprozesse. Denn durch das lineare Vorgehen werden Störungen im Produktionsablauf minimiert und die Implementierung stark auf den konkreten Prozess angepasst. Gleichzeitig ermöglicht es ein agiles Arbeiten in der Softwareentwicklung. Dadurch ist das Vorgehensmodell in der Lage, schnell und unbürokratisch auf Veränderungen in den Anforderungen einzugehen und gleichzeitig die Ansprüche an Robustheit und Dokumentation im industriellen Umfeld zu erfüllen.
Anmerkungen
- Fraunhofer IOSB – Machine Learning for Production Kurzfassung. Online unter: https://www.iosb.fraunhofer.de/content/dam/iosb/iosbtest/documents/projekte/ml4p/ML4P_whitepaper.pdf (abgerufen am 09.12.2020)











