

Für die digitale Neu- und Umplanung sowie für den Fabrikbetrieb mittels digitaler Zwillinge sind dreidimensionale Geometriemodelle des Betrachtungsbereiches eine wesentliche Grundlage. Insbesondere bei bestehenden großen oder komplexen Anlagen ist der händische Modellierungsaufwand immens. Wir erklären, wie Sie Modelle mittels Photogrammetrie nahezu vollständig automatisiert erstellen.
In diesem Nachgelesen erfahren Sie:
- Was ist Photogrammetrie und wie kann ich sie einsetzen?
- Welche Software wird eingesetzt?
- Was ist bei der Umsetzung zu beachten?
- Wie erhalte ich gute Ergebnisse?
Photogrammetrie
Die Photogrammetrie ist eine Methode, um durch berührungslose Messung aus verschiedenen Blickwinkeln eine digitale und maßgenaue 3D-Repräsentation zu erhalten. Hauptsächlich werden dazu Fotos genutzt, es existieren aber ebenso Ansätze zur zusätzlichen Einbeziehung von Tiefenkameras oder Laserscannern[1]. Der Einsatz zusätzlicher Hardware führt zu einer gesteigerten Genauigkeit des erzeugten digitalen Abbildes. Ein weiterer Ansatz zur Qualitätssteigerung, der ebenfalls den Berechnungsaufwand verringert, ist es, eine kalibrierte Kamera zu verwenden. Im Kalibrierungsprozess wird die Abbildungsverzerrung von Kamera und Objektiv ermittelt, sodass diese in allen folgenden Aufnahmen kompensiert werden kann. Das in diesem Nachgelesen vorgestellte Verfahren schätzt die Abbildungsverzerrung, falls keine Informationen vorhanden sind. Für viele Anwendungsfälle ist die so erzielte Genauigkeit bei einer ausreichenden Anzahl an Aufnahmen völlig ausreichend.
Welche Vorteile bietet diese Technologie nun? Sie können mit überschaubarem manuellem Aufwand und etwas Berechnungszeit am Computer jedes physikalisch existierende Objekt dreidimensional „fotografieren“ und als digitales Modell verfügbar machen. Solche Modelle lassen sich für zahlreiche Anwendungsfälle nutzen:
- Computergenerierte Bilder (Rendering) und Visualisierung
- Effizientes Erstellen von 3D-Modellen von komplexen Objekten
- Erzeugen von Kopien oder maßstäblichen Modellen durch 3D-Druck
- Betrachtung durch eine räumlich weit entfernte Person
- Messungen (je nach geforderter Genauigkeit / konkret eingesetzter Technologie zur Aufnahme)
- Ansichtsmodelle (Mockups) für Einrichtung von Räumen, Wohnungen, Fabriken
Unter Beachtung der Hinweise am Ende dieses Nachgelesen können selbst mit der Kamera eines aktuellen Smartphones oder einer einfachen Spiegelreflexkamera bereits sehr gute Ergebnisse mit Genauigkeiten im Bereich von unter einem Zentimeter (für Nahaufnahmen) entstehen. Die Größe des aufzunehmenden Objektes wird im Wesentlichen durch die Rechenkapazität und den Arbeitsspeicher des verarbeitenden PCs limitiert. Grundsätzlich können auch sehr große Objekte wie Maschinen, Fahrzeuge oder Gebäude digitalisiert werden.
Grundlagen
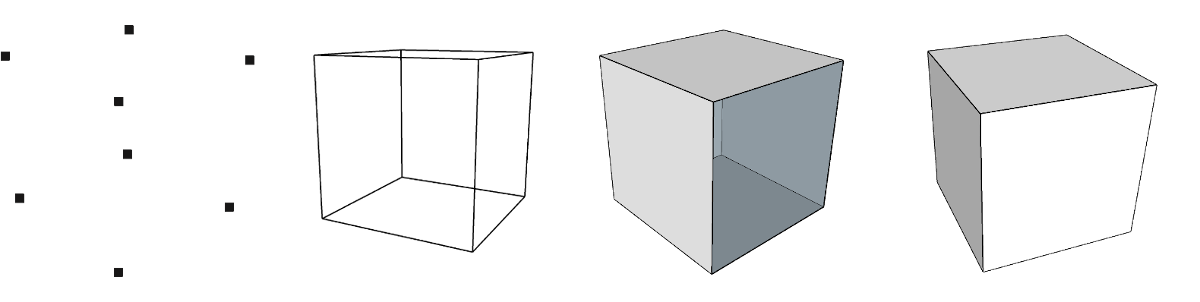
Zum besseren Verständnis des Verfahrens sollen in diesem Kapitel kurz einige Grundlagen der Repräsentation von dreidimensionalen Objekten im Computer dargelegt werden. In Abbildung 1 sind verschiedene Modellarten von dreidimensionalen Körpern dargestellt.
Die simpelste Möglichkeit der Beschreibung eines Körpers bietet eine dichte Punktewolke. Gleichzeitig ist dies das Datenformat, welches sich am schwierigsten weiterverarbeiten lässt. Es kann zwischen geordneten und ungeordneten Punktewolken unterschieden werden, je nachdem ob alle im Modell enthaltenen Punkte einen definierten Abstand haben. Dieses Format wird von den meisten Laserscannern erzeugt und hat zunächst keinerlei Informationen über die Flächen und Kanten zwischen den Punkten. Durch eine hohe Punktdichte können hochkomplexe Körper hinreichend genau beschrieben werden.
Das Kantenmodell ist ein Überbleibsel aus der Historie der Computergrafik und heutzutage weniger gebräuchlich (nur noch als ein Visualisierungsstil, abgeleitet von den Modellen), da ausreichend Rechenkapazität für Flächen und Volumenmodelle zur Verfügung steht. Es enthält im Gegensatz zur Punktwolke auch Informationen, welche Punkte (in der Computergrafik auch Vertex/Vertices) miteinander verbunden sind.
Ein Flächenmodell beschreibt einen Körper durch die Flächen, die ihn begrenzen. Komplexe Flächen (bspw. Freiformflächen) und Polygone werden aus vielen Teilflächen, in der Regel Dreiecken (Triangulation), zusammengesetzt. Dies führt bei hohen Detailgraden und komplexen Formen zu erhöhten Datenmengen. Falls sich „Löcher“ im Körper bzw. der Repräsentation aus zusammengesetzten Flächen ergeben, treten Inkonsistenzen im mathematischen Modell auf, die zu Fehlern in der Weiterverarbeitung führen können. Die Modelle sind „hohl“ und enthalten keine Informationen, welcher Teil der Fläche einen Körper abbildet.
Das Volumenmodell speichert zusätzlich zu den Flächen eines Körpers auch, auf welcher Seite der Fläche sich Materie befindet. Mit so repräsentierten Geometrien sind Volumenoperationen wie Addition und Subtraktion oder Verschneiden möglich, um mathematisch vollständig beschriebene komplexe Objekte zu erzeugen.
Das Endprodukt der Photogrammetrie ohne weitere Verarbeitung ist üblicherweise ein Flächenmodell mit einer sehr großen Anzahl an Flächen. Dieses Flächenmodell wird auch als Mesh bezeichnet.
Prozess der Photogrammetrie
In Abbildung 2 sind die einzelnen Schritte der Rekonstruktion im Rahmen einer Photogrammetrie in Anlehnung an die Darstellung von AliceVision[2] dargestellt.
Die Photogrammetrie ist mathematisch sehr komplex und hat viele Teilschritte. Die folgende Beschreibung ist trotz Verallgemeinerung noch sehr umfangreich. Zur Nutzung der Technologie ist das detaillierte Verständnis des Prozesses jedoch nicht notwendig. In späteren Abschnitten stellen wir Ihnen Software vor, die eine Anwendung sehr simpel möglich macht.

Merkmalsextraktion (Feature Extraction)
Ziel dieses Bearbeitungsschrittes ist es, Punkte / Bereiche in den einzelnen aufgenommenen Bildern zu finden, die bis zu einem gewissen Grad auch bei Betrachtung aus einem anderen Blickwinkel wiedererkennbar sind. Ein so gefundenes Merkmal hat die gleiche Beschreibung in verschiedenen Bildern des zu rekonstruierenden Objektes. Ein Algorithmus, der oft eingesetzt wird, ist SIFT (Scale-invariant feature transform). Teilschritte des Verfahrens erfordern die mehrfache Reduktion der Auflösung des bearbeiteten Bildes, sodass die Merkmalsextraktion ein sehr rechenintensiver Prozess ist. Je nach Beschaffenheit der Oberflächen im Bild können unter Umständen sehr viele Merkmale gefunden werden. Um den Berechnungsaufwand in folgenden Schritten zu reduzieren, wird auf Basis eines Filters die maximale Anzahl der Merkmale pro Bild begrenzt.
Bildabgleich (Image Matching)
Der Bildabgleich ist ein weiterer Vorverarbeitungsschritt um den, exponentiell zur Anzahl der zu verarbeitenden Merkmale wachsenden, Aufwand im nächsten Schritt zu reduzieren. Um zu vermeiden, jedes Merkmal gegen jedes andere Merkmal in allen Bildern vergleichen zu müssen, werden zunächst Bilder ausgewählt, die mit hoher Wahrscheinlichkeit gleiche Teile des aufzunehmenden Objektes zeigen. So können zunächst die gefundenen Kandidaten verarbeitet werden, um den gesamten Prozess zu beschleunigen.
Ein Ansatz, um das genannte Ziel zu erreichen, ist es, alle Merkmale in einer Baumstruktur zu speichern. Dabei wird ein Index für jedes einzigartige Merkmal vergeben. Nun lassen sich ähnliche Bilder leicht identifizieren – sie haben eine große Anzahl übereinstimmender Indizes für ihre Merkmale.
Merkmalsabgleich (Features Matching)
Wie bereits in den vorherigen Schritten angedeutet, ist es das Ziel des Merkmalsabgleichs, die Repräsentationen gleicher Merkmale in allen Bildern zu finden. Dazu werden zunächst die potentiellen Kandidaten für gleiche Merkmale in einem Paar von Bildern identifiziert. Dieser Vorgang ist auf Grund der hohen Anzahl an Kandidaten äußerst berechnungsintensiv und wird in mehreren Annäherungsschritten durchgeführt. Für jedes Merkmal im Bild 1 werden zunächst die beiden wahrscheinlichsten Kandidaten im Bild 2 gefunden. Für die finale Orientierung wird im Allgemeinen das RANSAC (RANdom SAmple Consensus) Framework genutzt. Dabei wird mit Hilfe einer Teilmenge der Merkmale eine Zuordnungshypothese zwischen den beiden Bildern erstellt und mit den verbleibenden Merkmalen geprüft. Über ein iteratives Vorgehen kann die Lösung dann Schritt für Schritt verbessert werden. Nachdem die ersten beiden Bilder abgeglichen wurden, wird nun das nächste Bild auf Basis der Ergebnisse aus dem Schritt Bildabgleich ausgewählt und hinzugefügt. Dieser Vorgang wird für alle Bilder wiederholt. Das Ergebnis ist ein Verständnis, in welchen Eingangsbildern jedes spezielle Merkmal an welcher Position auftritt.
Structure from Motion Algorithmus
Aufbauend auf dem Ergebnis des Merkmalabgleichs wird durch den Structure from Motion Algorithmus versucht, die vollständige dreidimensionale Repräsentation des aufgenommenen Objektes zu berechnen. Als zusätzliches Ergebnis lässt sich ebenfalls die Aufnahmeposition und -orientierung der Kamera für jedes einzelne Bild ableiten.
Der Structure from Motion Algorithmus ist ein iteratives Vorgehen. Ausgehend von den beiden Bildern mit der höchsten Merkmalsübereinstimmung aus dem Merkmalsabgleich und einem hinreichend großen Abstand zwischen den Aufnahmepunkten im Raum, wird für alle korrespondierenden Merkmale der Bilder eine Verbindung angelegt. Nun werden Schritt für Schritt weitere Bilder hinzugefügt, um ein Grobmodell zu erhalten und Ungewissheiten zu reduzieren. In diesem Grobmodell wird dann das beste Startbildpaar für die finale hochwertige Rekonstruktion gesucht. Das Startbildpaar bestimmt den Ursprung des finalen 3D-Objektes. Durch Triangulation zwischen den beiden Bildern werden übereinstimmende Bildpunkte im Raum platziert. Nun erfolgt abwechselnd die Suche nach Bildern, die auf Basis ihrer Merkmale eine hohe Übereinstimmung mit den bisher in 3D-rekonstruierten Punkten haben, das Hinzufügen dieser Bilder zum Modell und die Optimierung des Gesamtmodells auf Basis der neu verfügbaren Informationen. Durch die neu hinzugefügten Bilder gibt es nun neue Ursprungsbilder mit hoher Übereinstimmung, sodass die Schleife so lange von vorne beginnen kann, bis alle verfügbaren Bilder verarbeitet sind.
Berechnung der Tiefenkarte (Depth Maps Estimation)
Ausgehend von der dreidimensionalen Repräsentation des aufgenommenen Objekts wird in diesem Schritt für jedes Pixel in jedem Ursprungsbild die Entfernung zwischen Kamera und aufgenommenen Objekt (Tiefenkarte) ermittelt. Zur Steigerung der Genauigkeit erfolgt jeweils die Berechnung auf Basis umliegender Kamerapositionen für jedes Einzelbild. Die Schnittpunkte der optischen Achsen korrespondierender Pixel in den verschiedenen Kamerabildern erzeugen mehrere potentielle Entfernungskandidaten. Durch Rückprojektion vom Hauptbild in die benachbarten Bilder, Filterung und weitere Kreuzvalidierung wird ein Konsens der Entfernungswerte gebildet und abgespeichert.
Vernetzung (Meshing)
Bis zu diesem Schritt ist die 3D-Repräsentation des Objektes eine Punktewolke. Durch die Vernetzung entsteht aus dieser ein Flächenmodell. Es gibt zahlreiche Algorithmen, um dieses Problem zu lösen. Ein Ansatz kann sein, Flächen auf Basis der berechneten Tiefenkarten zu erzeugen. Dazu werden die Tiefenkarten der einzelnen Bilder in einem Modell (Octree) zusammengeführt. Mit Hilfe dieser Darstellung lassen sich benachbarte Punkte schnell und ressourceneffizient finden. Der folgende Prozess der Triangulation – das Verbinden von drei benachbarten Punkten zu einem Dreieck der neuzuberechnenden Oberfläche – ist nicht in jedem Fall eindeutig lösbar, sodass anschließend ein Filterungsschritt zum Entfernen von Artefakten notwendig wird. Je nach Anwendungsfall wird das so erzeugte Modell noch gefiltert, um die Anzahl an erzeugten Dreiecken zu reduzieren. So lässt sich die Performance bei der Darstellung und Weiterverarbeitung des Modells erhöhen.
Texturierung (Texturing)
Der letzte Schritt in der Verarbeitungskette hat zum Ziel, eine Textur für das berechnete Flächenmodell zu erzeugen. Dazu ist erneut ein Mittelwert notwendig. Für jedes Dreieck des 3D-Objekts werden alle Ursprungsbilder, die möglichst parallel zur Dreiecksebene liegen, ausgewählt. Aus den gewichteten Mittelwerten der korrespondierenden Pixel der einzelnen Ursprungsbilder wird so eine Textur für dieses Dreieck erzeugt. Durch die automatische Vergabe von Texturkoordinaten können dann die einzelnen Texturen für alle Dreiecke in einer großen Texturdatei abgelegt werden.
Nach diesen Schritten kann nun eine maßgenaue, farbige und dreidimensionale virtuelle Repräsentation des ursprünglich aufgenommenen Objektes abgespeichert werden.
Software für den Selbstversuch
Um den im vorherigen Kapitel beschriebenen Ablauf zu nutzen, gibt es verschiedene Softwareoptionen. Neben kommerziell erhältlichen Paketen von Anbietern großer CAD-Systeme oder aus dem Bereich der Geovermessung, existieren auch einige sehr leistungsfähige Open Source Implementierungen, die vollständig kostenlos sind. Zusammen mit der Nutzung eins Smartphones als Aufnahmegerät ist die Einstiegsschwelle für die Photogrammetrie somit äußerst niedrig. Zur Verarbeitung von Bildern aus einem Smartphone bietet sich Meshlab[3] als Software an. Dort können alle Fotos einfach importiert werden. Alle weiteren Schritte sind bereits vorkonfiguriert, sodass Sie nur noch den Startbutton betätigen und sich, je nach Anzahl der Bilder, einige Minuten oder Stunden gedulden müssen. Der Algorithmus in Meshlab ist standardmäßig nicht auf einen speziellen Anwendungsfall optimiert und bietet so eine gute allgemeine Lösung. Für Experten gibt es ein knotenbasiertes Konfigurationssystem, um die Abläufe den eigenen Vorstellungen und Erfordernissen anzupassen.
Anwendungsbeispiele
Das folgende Kapitel zeigt Ihnen die Möglichkeiten und Bandbreite der Photogrammetrie auf. Daher zeigen wir Ihnen Rekonstruktionen eines kleinen / mittleren Objektes (Produkt, Anlage etc.) bis hin zum zweiten Beispiel, der Modellerstellung einer kompletten Liegenschaft.
Die Aufnahmen des kleinen Modells wurden mit einem iPhone 7 Plus durchgeführt, die Aufnahmen des Geländes der Technischen Universität Chemnitz erfolgten mit einer DJI Mavic Pro Drohne.
Modellierung einer Bestandanlage
Das erste Beispiel ist die Digitalisierung eines Objektes aus unserem Maschinenbestand. Durch die Details wäre eine Nachmodellierung aufwendig. Für die 3D-Rekonstruktion wurden 104 Fotos aus verschiedensten Winkeln erstellt. Der Zeitaufwand dafür betrug etwa 10 Minuten. Abbildung 3 zeigt links einen Ausschnitt der aufgenommenen Bilder. Auf der rechten Seite sind die ermittelten Merkmale nach dem Berechnungsschritt Merkmalsextraktion als rote und orange Punkte dargestellt. Auffällig ist hier, dass im Bereich der flachen Flächen deutlich weniger Merkmale gefunden werden konnten. Dieses Problem wird durch die ebene und farblich homogene Oberfläche verursacht.

In Abbildung 4 sind links die berechneten Kamerapositionen sowie die ermittelten Schnittpunkte nach dem Schritt „Structure from Motion“ dargestellt. Mittig findet sich das fertige Ergebnis der Rekonstruktion nach einer Berechnungsdauer von etwa 3 Stunden, ein texturiertes dreidimensionales Modell, rechts das gleiche Modell nach der Freistellung. Es ist gut erkennbar, dass im oberen Bereich nicht genug Fotos vorhanden waren, um die Rekonstruktion perfekt verlaufen zu lassen. Abhilfe könnten hier eine Optimierung der Parameter des Algorithmus, weitere Fotos oder das Aufbringen von zusätzlichen Markierungen, zum Beispiel mit Kreidespray, schaffen.

Aufnahmen Institut für Betriebswissenschaften
Als zweites Beispiel wurde ein ca. 12.000 m² großer Bereich des Geländes der Technischen Universität Chemnitz digitalisiert. Abbildung 5 zeigt die Flugroute der Drohne und den Bereich, der gescannt wurde. Im Hintergrund ist noch die Karte von Google Maps erkennbar. Die Flugzeit inklusive Aufnahmen betrug etwa 50 Minuten.
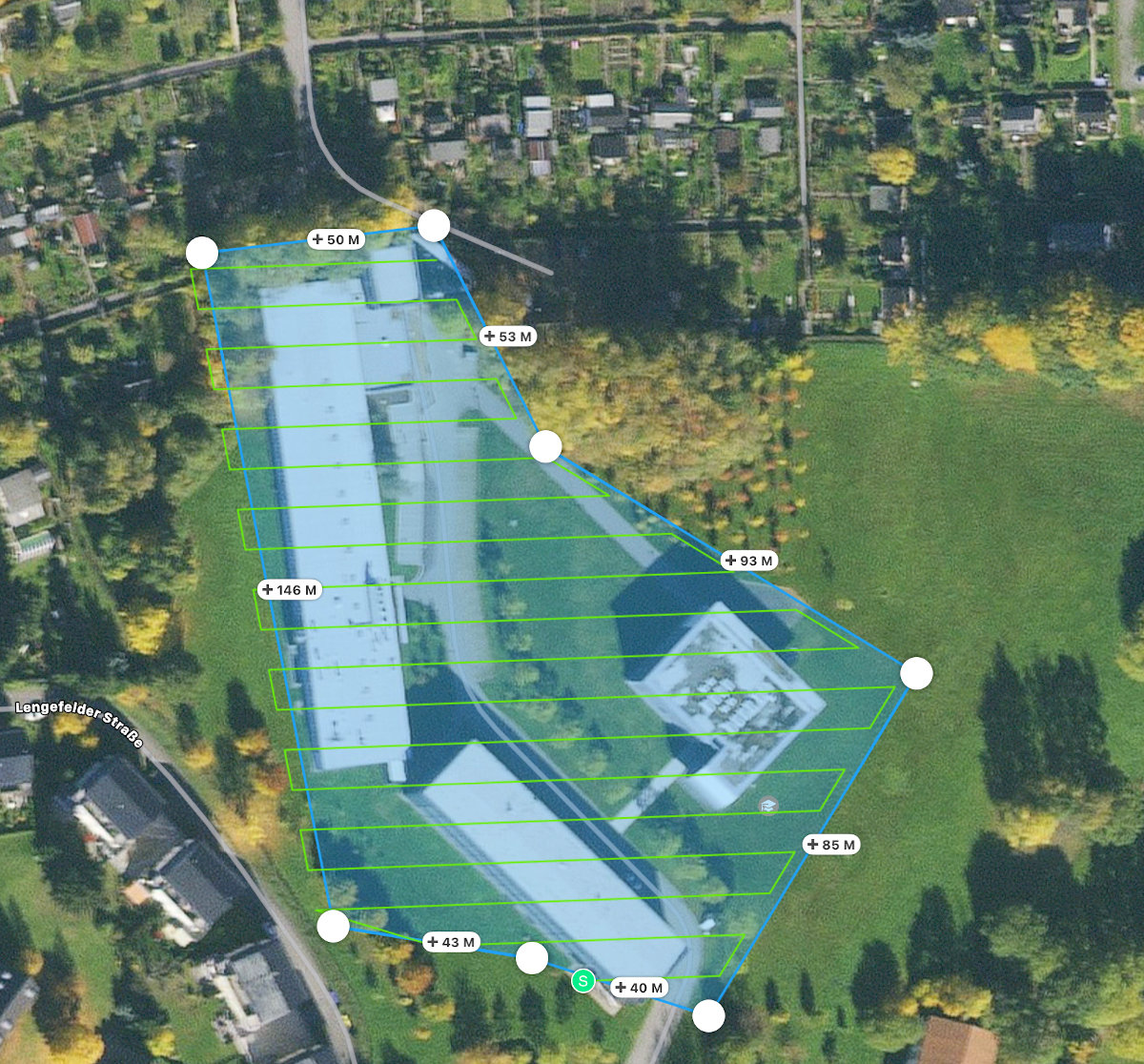
Durch die notwendige Überlappung der einzelnen Bilder in beiden Achsen entstanden 534 Aufnahmen. Einen kleinen Überblick dazu zeigt Abbildung 6.

Nach etwa 4 Stunden Berechnungszeit durch Open Drone Map konnten die in Abbildung 7 und Abbildung 8 dargestellten Ergebnisse abgerufen werden.

Die Detailierung in Abbildung 8 an jeder beliebigen Stelle ist enorm. Mit dieser Technik können selbst feine Veränderungen an Objekten im Laufe der Zeit durch mehrere Aufnahmen dokumentiert werden.

Best Practices
Um die Erfolgsquote bei einer Photogrammetrie zu erhöhen, können schon bei der Aufnahme einige Punkte beachtet werden. Diese Schritte unterstützen die Berechnungen und steigern so die Qualität des Ergebnisses.
- Die Auflösung der Aufnahmen sollte 5 MP oder mehr betragen.
- Stellen Sie die Kamera auf manuellen Weißabgleich und versuchen Sie alle Bilder mit gleicher Belichtung aufzunehmen. Starke Varianz muss mit Hilfe von Bildbearbeitungssoftware korrigiert werden.
- Falls die Aufnahmen längere Zeit in Anspruch nehmen, versuchen Sie konstante Beleuchtung über die Fotoserie zu erreichen. Sonnenlicht erzeugt wandernde Schatten, die zu Zuordnungsfehlern führen können. Künstliche Beleuchtung oder Aufnahmen an einem bedeckten Tag vereinfachen den Prozess.
- Idealerweise findet keine Bewegung im Aufnahmebereich zwischen den Aufnahmen statt. Besonders Objekte, die sich im Wind bewegen, wie Grashalme oder Blätter, sind mitunter problematisch.
- Versuchen Sie Objekte mit einer möglichst großen Varianz in der Oberfläche und Färbung zu finden. Ebene Flächen ohne Variation machen das Auffinden von Merkmalen kompliziert. Vermeiden Sie nach Möglichkeit glatte Wände, große Asphaltflächen ohne Markierung, durchsichtige und stark reflektierende Oberflächen.
- Insbesondere bei Nahfeldaufnahmen: Versuchen Sie zunächst das Objekt von Interesse von allen Seiten im Ganzen zu fotografieren, danach erfolgen Detailaufnahmen einzelner Bereiche aus verschiedenen Entfernungen.
- Versuchen Sie alle relevanten Bereiche aus mehreren Winkeln aufzunehmen. Bereiche, die in keinem Bild sichtbar sind, führen zu Artefakten oder Löchern in der Rekonstruktion.
- Vermeiden Sie extreme Verzerrungen und Perspektiven im Bild.
- Nehmen Sie lieber zu viele Bilder auf als zu wenige. Für Nahaufnahmen sind 50-300 Bilder eine gute Richtgröße.
- Bevor der Algorithmus gestartet wird, prüfen Sie Ihre Bilder noch einmal. Unscharfe Bilder müssen unbedingt aussortiert werden. Ein defektes Bild kann den gesamten Prozess fehlschlagen lassen.
Wir hoffen, Ihnen durch dieses Nachgelesen die Technologie Photogrammetrie näher gebracht zu haben und Sie dazu zu inspirieren einen Anwendungsfall in Ihrem Geschäftsbereich zu finden. Mit den beschriebenen Methoden, Werkzeugen und Hinweisen sollte der Einstieg in einen Selbstversuch möglich sein. Falls dennoch Fragen oder Probleme auftreten, kontaktieren Sie uns gern.
Quellen, Anmerkungen und weiterführende Literatur
- Sajinkumar K.S., Oommen T. (2018) Photogrammetry. In: Bobrowsky P., Marker B. (eds) Encyclopedia of Engineering Geology. Encyclopedia of Earth Sciences Series. Springer, Cham. https://doi.org/10.1007/978-3-319-12127-7_221-1
- AliceVision (2020): Photogrammetry Pipeline. Abgerufen von: https://alicevision.org/#photogrammetry
- Meshroom (2020): Photogrammetry Software. Abgerufen von: https://alicevision.org/#meshroom
- Open Drone Map (2020): Photogrammetry Software für Dronenaufnahen. Abgerufen von: https://www.opendronemap.org/











